Kardiovaskularne bolesti (KVB) su jedan od vodećih uzroka smrti širom sveta i hitno su potrebni odgovori u vezi sa mnogim aspektima, posebno identifikacijom rizika i predviđanjem prognoze. Studije iz stvarnog sveta sa velikim brojem opservacija pružaju važnu osnovu za istraživanje KVB, ali su ograničene visokom dimenzionalnošću i nedostajućim ili nestrukturiranim podacima.
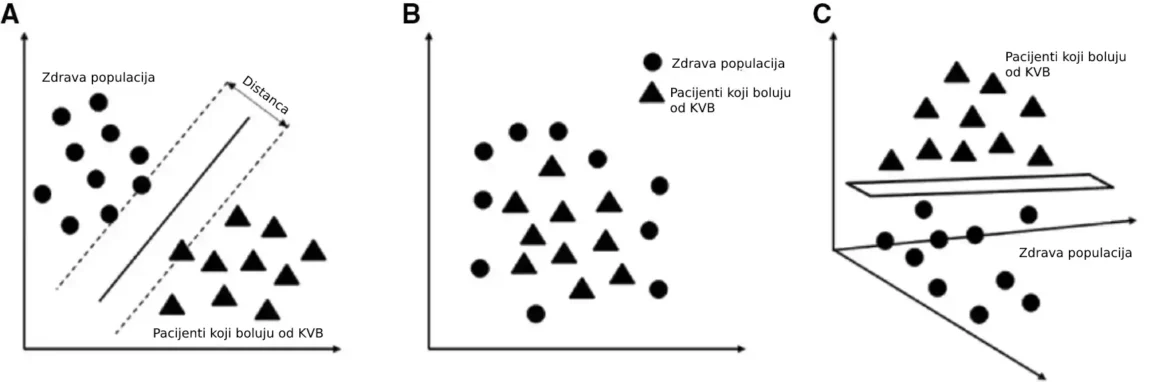
Metode mašinskog učenja (ML), uključujući razne nadzirane i nenadzirane algoritme, korisne su za upravljanje podacima i efikasne su za analizu podataka visokih dimenzija i imputaciju u studijama u stvarnom svetu. Ovaj članak daje pregled teorije, prednosti i ograničenja, kao i primene nekoliko najčešće korišćenih metoda ML u oblasti KVB, kako bi pružio referencu za dalju primenu.
Ovaj članak uvodi poreklo, svrhu, teoriju, prednosti i ograničenja i primene više često korišćenih ML algoritama, uključujući hijerarhijsko i k-means klasterisanje, analizu glavnih komponenti, slučajnu šumu, mašinu za podršku vektorima i neuronske mreže. Primer koristi slučajnu šumu na podacima ispitivanja intervencije sistolnog krvnog pritiska (SPRINT) da bi se demonstrirao proces i glavne rezultate primene ML u KVB.
ML metode su efikasna oruđa za proizvodnju dokaza iz stvarnog sveta koji podržavaju kliničke odluke i zadovoljavaju kliničke potrebe. Ovaj pregled objašnjava principe višestrukih ML metoda na jednostavnom jeziku, kako bi pružio referencu za dalju primenu. Buduća istraživanja su opravdana za razvoj tačnih metoda učenja ansambla za široku primenu u oblasti medicine.
Studija je objavljena u časopisu Cardiovascular Innovations and Applications.


