Oblast mašinskog učenja tradicionalno je podeljena u dve glavne kategorije: „nadgledano“ i „nenadgledano“ učenje. U kontrolisanom učenju, algoritmi se obučavaju na označenim podacima, gde je svaki ulaz uparen sa odgovarajućim izlazom, dajući algoritmu jasne smernice. Nasuprot tome, učenje bez nadzora oslanja se isključivo na ulazne podatke, zahtevajući da algoritam otkrije obrasce ili strukture bez ikakvih označenih izlaza.
Poslednjih godina pojavila se nova paradigma poznata kao „samokontrolisano učenje“ (SSL), koja zamagljuje granice između ovih tradicionalnih kategorija. Učenje pod nadzorom u velikoj meri zavisi od ljudskih stručnjaka koji označavaju podatke i služe kao „supervizor“. Međutim, SSL zaobilazi ovu zavisnost koristeći algoritme za automatsko generisanje oznaka iz neobrađenih podataka.
SSL algoritmi se koriste za širok spektar primena, od obrade prirodnog jezika (NLP) do kompjuterskog vida, bioinformatike i prepoznavanja govora. Tradicionalni SSL pristupi podstiču predstavljanje semantički sličnih (pozitivnih) parova da budu bliske, a one različitih (negativnih) parova da budu udaljenije.
Pozitivni parovi se obično generišu korišćenjem standardnih tehnika povećanja podataka kao što su nasumično podešavanje boje, teksture, orijentacije i izrezivanja. Usklađivanje reprezentacija za pozitivne parove može biti vođeno ili invarijantnošću, koja promoviše neosetljivost na ova povećanja, ili ekvivarijansom, koja održava osetljivost na njih.
Izazov je, međutim, u tome što sprovođenje invarijantnosti ili ekvivarijanse unapred definisanog skupa povećanja uvodi jake „induktivne pretpostavke“ – inherentne pretpostavke o svojstvima koja naučene reprezentacije moraju da zadovolje – koje su daleko od univerzalnih u nizu nizvodnih vrednosti. zadataka.
U radu objavljenom na arKsiv serveru za preprint, tim iz Laboratorije za računarske nauke i veštačku inteligenciju MIT-a (CSAIL) i Tehničkog univerziteta u Minhenu predložili su novi pristup samonadziranom učenju koji se bavi ovim ograničenjima oslanjanja na unapred definisane podatke. augmentacije, i umesto toga uči iz opšte reprezentacije koja se može prilagoditi različitim transformacijama obraćajući pažnju na kontekst, koji predstavlja apstraktni pojam zadatka ili okruženja.
Ovo omogućava učenje reprezentacija podataka koje su fleksibilnije i prilagodljivije za različite nizvodne zadatke, različite simetrije i osetljive karakteristike, eliminišući potrebu za ponovnim obučavanjem za svaki zadatak.
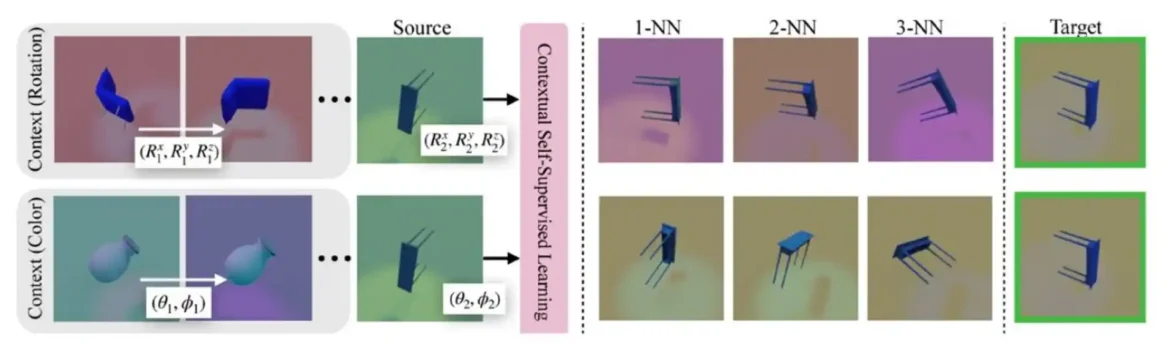
Nazivajući svoj metod „kontekstualno samokontrolisano učenje“ (ContextSSL), istraživači demonstriraju njegovu efikasnost kroz opsežne eksperimente na nekoliko skupova podataka. Osnovna ideja je da se uvede kontekst inspirisan svetskim modelima—predstavama agentovog okruženja koje obuhvataju njegovu dinamiku i strukturu.
Uključujući ove svetske modele, pristup omogućava modelu da dinamički prilagodi svoje reprezentacije da budu invarijantne ili ekvivarijantne na osnovu zadatka. Ovo eliminiše potrebu za obukom odvojenih reprezentacija za svaki nizvodni zadatak i omogućava opštiji i fleksibilniji pristup SSL-u.
ContextSSL koristi transformatorski modul za kodiranje konteksta kao niza tripleta stanje-akcija-sledeće stanje, koji predstavljaju prethodna iskustva sa transformacijama. Posmatrajući kontekst, model uči da selektivno sprovodi invarijantnost ili ekvivarijansu na osnovu transformacione grupe predstavljene u kontekstu.
„Konkretno, naš cilj je da obučimo reprezentacije koje postaju više ekvivalentne osnovnoj transformacionoj grupi sa sve većim kontekstom“, kaže dr. CSAIL. student Sharut Gupta, glavni autor novog rada od istraživača koji uključuju profesore MIT-a Tommi Jaakkola i Stefanie Jegelka. „Ne želimo da svaki put fino podešavamo modele, već da izgradimo fleksibilan model opšte namene koji bi mogao da se bavi različitim okruženjima sličnim ljudima.“
ContextSSL demonstrira značajna poboljšanja performansi na nekoliko benčmarka računarskog vida, uključujući 3DIEBench i CIFAR-10, za zadatke koji zahtevaju i invarijantnost i ekvivarijansu. U zavisnosti od konteksta, reprezentacija koju je naučio ContextSSL prilagođava se pravim karakteristikama koje su bile korisne za dati nizvodni zadatak.
Kao primer, tim je testirao sposobnost ContextSSL-a da nauči reprezentacije za određeni atribut pola na MIMIC-III, velikoj kolekciji medicinske dokumentacije koja uključuje ključne identifikatore kao što su lekovi, demografija pacijenata, dužina boravka u bolnici (LOS) i podaci o preživljavanju .
Tim je istražio ovaj skup podataka jer obuhvata zadatke iz stvarnog sveta koji imaju koristi i od ekvivarijanse i od invarijantnosti: ekvivarijansa je ključna za zadatke kao što je medicinska dijagnoza gde doze lekova zavise od pola i fizioloških karakteristika pacijenata, dok je invarijantnost od suštinskog značaja za osiguranje pravičnosti u predviđanju ishoda kao što je dužina boravka u bolnici ili medicinskih troškova.
Istraživači su na kraju otkrili da, kada ContextSSL vodi računa o kontekstu koji promoviše rodnu osetljivost, i tačnost predviđanja roda i predviđanje medicinskog tretmana se poboljšavaju sa kontekstom. Naprotiv, kada kontekst promoviše invarijantnost, učinak se poboljšava na osnovu predviđanja dužine boravka u bolnici (LOS) i različitih metrika pravednosti merenih izjednačenim kvotama (EO) i jednakosti mogućnosti (EOPP).
„Ključni cilj samonadgledanog učenja je da generiše fleksibilne reprezentacije koje se mogu prilagoditi mnogim nizvodnim zadacima“, kaže viši naučnik Google DeepMind za istraživanje Dilip Krišnan, koji nije bio uključen u rad. „Umesto da se peče u invarijantnosti ili ekvivarijansi a priori, mnogo je korisnije odlučiti o ovim svojstvima na način specifičan za zadatak.
„Ovaj zanimljiv rad čini važan korak u ovom pravcu. Pametnim korišćenjem sposobnosti učenja u kontekstu transformatorskih modela, njihov pristup se može koristiti za nametanje invarijantnosti ili ekvivarijanse različitim transformacijama na jednostavan i efikasan način.“


