Da bi se izgradili sistemi veštačke inteligencije koji mogu efikasno da sarađuju sa ljudima, za početak pomaže imati dobar model ljudskog ponašanja. Ali ljudi imaju tendenciju da se ponašaju neoptimalno kada donose odluke.
Ova iracionalnost, koju je posebno teško modelirati, često se svodi na računska ograničenja. Čovek ne može da provede decenije razmišljajući o idealnom rešenju jednog problema.
Istraživači sa MIT-a i Univerziteta u Vašingtonu razvili su način za modeliranje ponašanja agenta, bilo čoveka ili mašine, koji objašnjava nepoznata računarska ograničenja koja mogu ometati agentove sposobnosti rešavanja problema.
Njihov model može automatski da zaključi računska ograničenja agenta tako što će videti samo nekoliko tragova njihovih prethodnih radnji. Rezultat, takozvani agentov „budžet zaključivanja“, može se koristiti za predviđanje budućeg ponašanja tog agenta.
U novom radu, istraživači pokazuju kako se njihov metod može koristiti za zaključivanje nečijih navigacijskih ciljeva iz prethodnih ruta i za predviđanje budućih poteza igrača u šahovskim mečevima. Njihova tehnika odgovara ili nadmašuje drugu popularnu metodu za modeliranje ove vrste donošenja odluka.
Na kraju, ovaj rad bi mogao pomoći naučnicima da nauče AI sisteme kako se ljudi ponašaju, što bi moglo omogućiti ovim sistemima da bolje reaguju na svoje ljudske saradnike. Biti u stanju da razume ljudsko ponašanje, a zatim da zaključi njihove ciljeve iz tog ponašanja, moglo bi da učini pomoćnika veštačke inteligencije mnogo korisnijim, kaže Atul Pol Džejkob, diplomirani student elektrotehnike i računarstva (EECS) i glavni autor rada o ovu tehniku.
„Ako znamo da će čovek pogrešiti, pošto smo ranije videli kako se ponašao, AI agent bi mogao da uskoči i ponudi bolji način da to uradi. Ili bi se agent mogao prilagoditi slabostima koje imaju njegovi ljudski saradnici Biti u stanju da modelira ljudsko ponašanje je važan korak ka izgradnji AI agenta koji zapravo može pomoći tom čovjeku.
Jacob je napisao rad sa Abhišekom Guptom, docentom na Univerzitetu u Vašingtonu, i starijim autorom Jacobom Andreasom, vanrednim profesorom u EECS i članom Laboratorije za računarske nauke i veštačku inteligenciju (CSAIL). Istraživanje će biti predstavljeno na Međunarodnoj konferenciji o reprezentacijama učenja (ICLR 2024), održanoj u Beču, Austrija, 7–11.
Istraživači su decenijama gradili računarske modele ljudskog ponašanja. Mnogi prethodni pristupi pokušavaju da uzmu u obzir suboptimalno donošenje odluka dodavanjem buke u model. Umesto da agent uvek bira ispravnu opciju, model bi mogao da natera tog agenta da napravi ispravan izbor u 95% vremena.
Međutim, ove metode ne mogu da uhvate činjenicu da se ljudi ne ponašaju uvek neoptimalno na isti način.
Drugi na MIT-u su takođe proučavali efikasnije načine planiranja i zaključivanja ciljeva u uslovima neoptimalnog donošenja odluka.
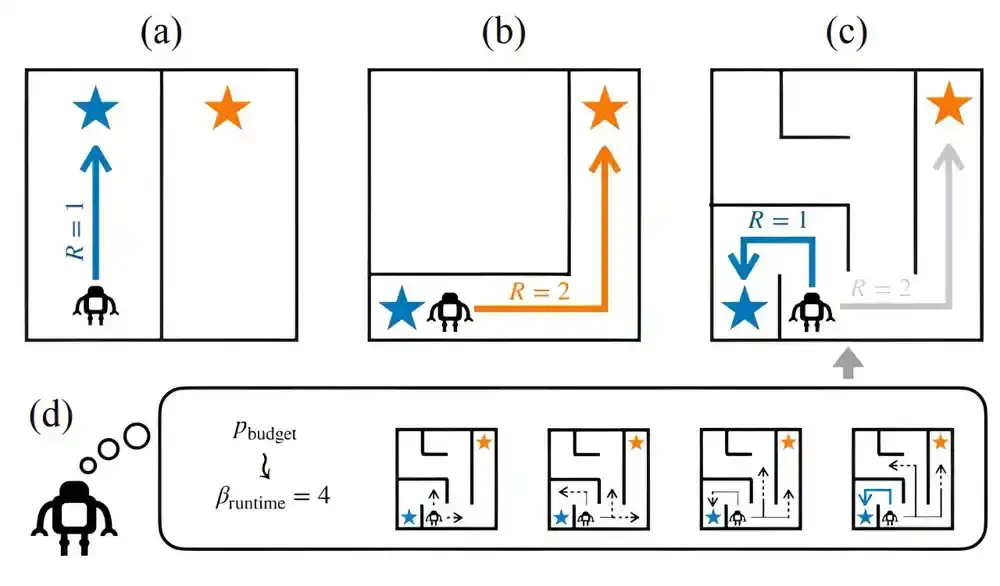
Da bi izgradili svoj model, Jacob i njegovi saradnici su crpili inspiraciju iz prethodnih studija šahista. Primetili su da igračima treba manje vremena da razmisle pre nego što reaguju kada prave jednostavne poteze i da jači igrači provode više vremena u planiranju od slabih u izazovnim mečevima.
„Na kraju dana, videli smo da je dubina planiranja, ili koliko dugo neko razmišlja o problemu, zaista dobar pokazatelj kako se ljudi ponašaju“, kaže Džejkob.
Izgradili su okvir koji bi mogao zaključiti dubinu agentovog planiranja iz prethodnih akcija i koristiti te informacije za modeliranje agentovog procesa donošenja odluka.
Prvi korak u njihovoj metodi uključuje pokretanje algoritma za određeno vreme za rešavanje problema koji se proučava. Na primer, ako proučavaju šahovsku utakmicu, možda će pustiti algoritam za igranje šaha da radi za određeni broj koraka. Na kraju, istraživači mogu da vide odluke koje je algoritam doneo u svakom koraku.
Njihov model poredi ove odluke sa ponašanjem agenta koji rešava isti problem. On će uskladiti odluke agenta sa odlukama algoritma i identifikovati korak u kojem je agent prestao da planira.
Iz ovoga, model može odrediti agentov budžet za zaključke, ili koliko dugo će taj agent planirati za ovaj problem. Može da koristi budžet zaključivanja da predvidi kako će taj agent reagovati kada reši sličan problem.
Ovaj metod može biti veoma efikasan jer istraživači mogu pristupiti celom skupu odluka koje donosi algoritam za rešavanje problema bez dodatnog rada. Ovaj okvir se takođe može primeniti na bilo koji problem koji se može rešiti određenom klasom algoritama.
„Za mene je najupečatljivija bila činjenica da je ovaj budžet za zaključak veoma razumljiv. On kaže da teži problemi zahtevaju više planiranja ili biti jak igrač znači planirati duže. Kada smo prvi put krenuli da uradimo ovo, nismo mislim da bi naš algoritam mogao prirodno da shvati ta ponašanja“, kaže Džejkob.
Istraživači su testirali svoj pristup u tri različita zadatka modeliranja: zaključivanje ciljeva navigacije iz prethodnih ruta, pogađanje nečije komunikativne namere iz njihovih verbalnih znakova i predviđanje narednih poteza u šahovskim mečevima između ljudi i ljudi.
Njihov metod je odgovarao ili nadmašio popularnu alternativu u svakom eksperimentu. Štaviše, istraživači su videli da se njihov model ljudskog ponašanja dobro poklapa sa merama veštine igrača (u šahovskim mečevima) i težine zadataka.
Idući dalje, istraživači žele da koriste ovaj pristup za modeliranje procesa planiranja u drugim domenima, kao što je učenje uz pomoć (metoda pokušaja i greške koja se obično koristi u robotici). Dugoročno, oni nameravaju da nastave da se nadograđuju na ovaj rad ka širem cilju razvoja efikasnijih AI saradnika.


