Da bi naučili AI agenta novom zadatku, kao što je kako da otvori kuhinjski ormarić, istraživači često koriste učenje sa pojačanjem – proces pokušaja i grešaka gde je agent nagrađen za preduzimanje radnji koje ga približavaju cilju.
U mnogim slučajevima, stručnjak za ljude mora pažljivo da osmisli funkciju nagrađivanja, što je mehanizam podsticaja koji agentu daje motivaciju da istražuje. Stručnjak za ljude mora iterativno ažurirati tu funkciju nagrađivanja dok agent istražuje i pokušava različite akcije. Ovo može biti dugotrajno, neefikasno i teško ga je povećati, posebno kada je zadatak složen i uključuje mnogo koraka.
Istraživači sa MIT-a, Univerziteta Harvard i Univerziteta u Vašingtonu razvili su novi pristup učenju uz pomoć koji se ne oslanja na stručno dizajniranu funkciju nagrađivanja. Umesto toga, on koristi povratne informacije iz grupe, prikupljene od mnogih nestručnih korisnika, kako bi vodio agenta dok uči da postigne svoj cilj. Rad je objavljen na serveru za pre-print arKsiv.
Dok neke druge metode takođe pokušavaju da iskoriste povratne informacije koje nisu stručne, ovaj novi pristup omogućava AI agentu da uči brže, uprkos činjenici da su podaci dobijeni od korisnika često puni grešaka. Ovi bučni podaci mogu dovesti do neuspeha drugih metoda.
Pored toga, ovaj novi pristup omogućava asinhrono prikupljanje povratnih informacija, tako da nestručni korisnici širom sveta mogu da doprinesu podučavanju agenta.
„Jedan od najzahtjevnijih i najizazovnijih delova u dizajniranju robotskog agenta danas je projektovanje funkcije nagrađivanja. Današnje funkcije nagrađivanja dizajniraju stručni istraživači — paradigma koja nije skalabilna ako želimo da svoje robote naučimo mnogim različitim zadacima. rad predlaže način da se poveća učenje robota tako što će se dizajnirati funkcija nagrađivanja masovnim izvorima i omogućiti da nestručnjaci daju korisne povratne informacije“, kaže Pulkit Agraval, docent na MIT odsjeku za elektrotehniku i računarstvo (EECS) koji vodi Improbable AI Lab u MIT Laboratoriji za računarske nauke i veštačku inteligenciju (CSAIL).
U budućnosti, ovaj metod bi mogao pomoći robotu da nauči da brzo obavlja određene zadatke u kući korisnika, a da vlasnik ne mora da pokaže robotu fizičke primere svakog zadatka. Robot bi mogao sam da istražuje, uz pomoć nestručnih povratnih informacija koje bi vodile njegovo istraživanje.
„U našoj metodi, funkcija nagrađivanja vodi agenta do onoga što treba da istraži, umesto da mu kaže šta tačno treba da uradi da bi izvršio zadatak. Dakle, čak i ako je ljudski nadzor donekle netačan i bučan, agent je i dalje u stanju da istražuje, što mu pomaže da uči mnogo bolje“, objašnjava glavni autor Marsel Torne, istraživač-asistent u laboratoriji Improbable AI.
Torneu se u radu pridružuje njegov savetnik sa MIT-a, Agraval; viši autor Abhishek Gupta, docent na Univerzitetu u Vašingtonu; kao i drugi na Univerzitetu u Vašingtonu i MIT-u. Istraživanje će biti predstavljeno na Konferenciji o sistemima za neuralnu obradu informacija sledećeg meseca.
Jedan od načina da se prikupi povratna informacija korisnika za dodatno učenje je da se korisniku pokažu dve fotografije stanja koje je agent postigao, a zatim zamolite korisnike da navedu koje je bliže cilju. Na primer, možda je cilj robota da otvori kuhinjski ormarić. Jedna slika može pokazati da je robot otvorio ormar, dok druga može pokazati da je otvorio mikrotalasnu. Korisnik bi izabrao fotografiju „bolje“ države.
Neki prethodni pristupi pokušavaju da iskoriste ovu binarnu povratnu informaciju koja je bazirana na skupu radi optimizacije funkcije nagrađivanja koju bi agent koristio da nauči zadatak. Međutim, pošto nestručnjaci verovatno prave greške, funkcija nagrađivanja može postati veoma bučna, tako da agent može da zaglavi i nikada ne postigne svoj cilj.
„U suštini, agent bi previše ozbiljno shvatio funkciju nagrađivanja. Pokušao bi da savršeno uskladi funkciju nagrađivanja. Dakle, umesto da direktno optimizujemo funkciju nagrađivanja, mi je samo koristimo da kažemo robotu koja područja treba da istražuje“, Torne kaže.
On i njegovi saradnici razdvojili su proces u dva odvojena dela, od kojih je svaki upravljao sopstvenim algoritmom. Oni svoj novi metod učenja sa pojačanjem nazivaju HuGE (Human Guided Ekploration).
S jedne strane, algoritam za biranje ciljeva se kontinuirano ažurira uz pomoć ljudskih povratnih informacija. Povratne informacije se ne koriste kao funkcija nagrade, već da usmeravaju agentovo istraživanje. U izvesnom smislu, nestručni korisnici ispuštaju mrvice koje postepeno vode agenta ka njegovom cilju.
Sa druge strane, agent istražuje sam, na samonadzoran način vođen od strane selektora golova. Prikuplja slike ili video zapise radnji koje pokušava, koje se zatim šalju ljudima i koriste za ažuriranje birača ciljeva.
Ovo sužava oblast koju agent može istražiti, što ga dovodi do oblasti koje obećavaju koje su bliže njegovom cilju. Ali ako nema povratnih informacija ili ako povratnim informacijama treba neko vreme da stignu, agent će nastaviti da uči sam, iako na sporiji način. Ovo omogućava da se povratne informacije prikupljaju retko i asinhrono.
„Petlja istraživanja može da nastavi da se odvija autonomno, jer će samo da istražuje i uči nove stvari. A onda kada dobijete bolji signal, ona će istraživati na konkretnije načine. Možete ih zadržati da se okreću sopstvenim tempom “, dodaje Torne.
A pošto povratne informacije samo nežno usmeravaju ponašanje agenta, on će na kraju naučiti da završi zadatak čak i ako korisnici daju netačne odgovore.
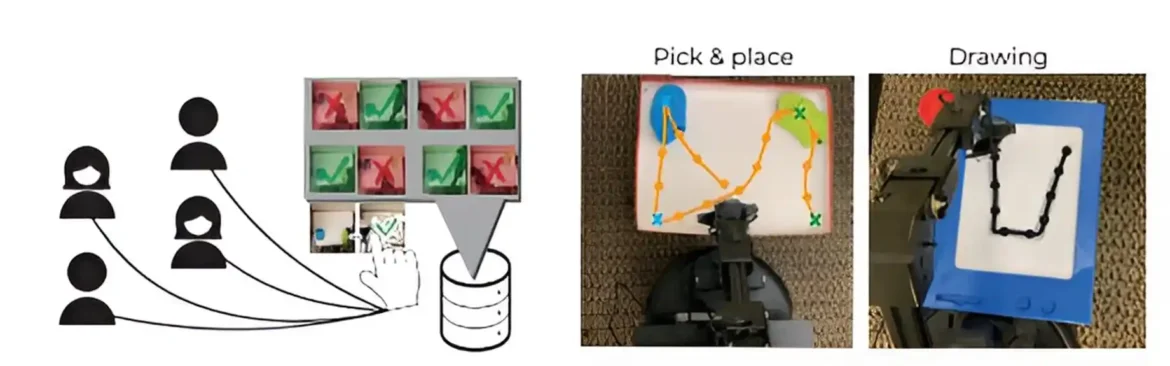
Istraživači su testirali ovu metodu na brojnim simuliranim i stvarnim zadacima. U simulaciji, koristili su HuGE da efikasno nauče zadatke sa dugim sekvencama akcija, kao što su slaganje blokova određenim redosledom ili navigacija velikim lavirintom.
U testovima u stvarnom svetu, koristili su HuGE da obuče robotske ruke da crtaju slovo „U“ i biraju i postavljaju predmete. Za ove testove, oni su prikupili podatke od 109 nestručnih korisnika u 13 različitih zemalja na tri kontinenta.
U realnim i simuliranim eksperimentima, HuGE je pomogao agentima da nauče da postignu cilj brže od drugih metoda.
Istraživači su takođe otkrili da su podaci prikupljeni od strane nestručnjaka dali bolje rezultate od sintetičkih podataka, koje su proizveli i označili istraživači. Za nestručne korisnike, označavanje 30 slika ili video zapisa trajalo je manje od dva minuta.
„To ga čini veoma obećavajućim u smislu mogućnosti da se ovaj metod proširi“, dodaje Torne.
U povezanom radu, koji su istraživači predstavili na nedavnoj Konferenciji o učenju robota, poboljšali su HuGE tako da AI agent može naučiti da izvrši zadatak, a zatim autonomno resetuje okruženje kako bi nastavio sa učenjem. Na primer, ako agent nauči da otvori kabinet, metoda takođe vodi agenta da zatvori kabinet.
„Sada možemo da ga naučimo potpuno autonomno bez potrebe za ljudskim resetovanjem“, kaže on.
Istraživači takođe naglašavaju da je, u ovom i drugim pristupima učenju, ključno osigurati da su AI agenti usklađeni sa ljudskim vrednostima.
U budućnosti žele da nastave da usavršavaju HuGE kako bi agent mogao da uči iz drugih oblika komunikacije, kao što su prirodni jezik i fizičke interakcije sa robotom. Takođe su zainteresovani za primenu ove metode za podučavanje više agenata odjednom.


