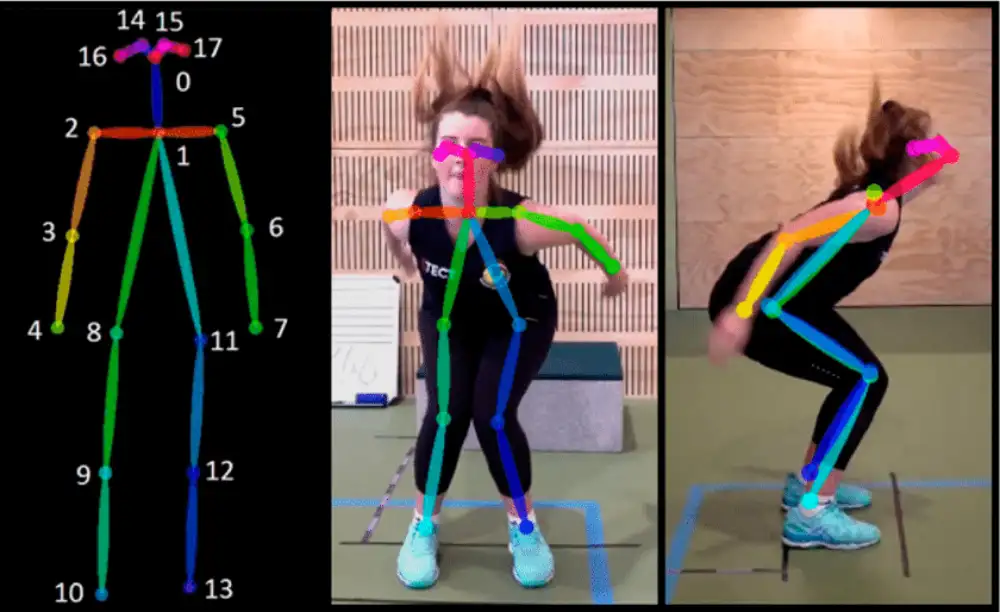
Precizna procena 3D poza i oblika tela sa jedne slike je kritična za nekoliko aplikacija, kao što su analiza ponašanja i bezbednosna upozorenja. Nažalost, mnoge postojeće metode rekonstrukcije sa više osoba zahtevaju da prisutni ljudi budu jasno vidljivi na fotografiji kako bi pružili dovoljno informacija. Ovo postaje problem kada kamere imaju ograničenu rezoluciju i vidno polje se povećava da bi se uhvatili pojedinci u udaljenim oblastima, što rezultira slikama niske rezolucije koje pružaju malo informacija.
Da bi rešio to ograničenje, istraživački tim sa Univerziteta Tianjin i Univerziteta u Kardifu pokušao je da pomiri konflikt između rezolucije slike i tačnosti procene. Kako je objavljeno u časopisu KeAi Fundamental Research, tim je predložio end-to-end okvir za mašinsko učenje sa više zadataka poznat kao MILI (zaključivanje za više osoba iz slike niske rezolucije) koji omogućava preciznu 3D pozu i predstavljanje oblika za više osoba sa slike niske rezolucije.
Dalje, da bi se pozabavili problemom okluzije u scenama sa više osoba, istraživači su osmislili mrežu za predviđanje maski svesne okluzije za procenu maske mreže svake osobe tokom regresije. Za obuku su korišćene i slike u paru visoke i niske rezolucije.
„I u malim i u velikim scenama, MILI je nadmašio najsavremenije metode i kvantitativno i kvalitativno“, rekao je Kun Li, vodeći autor studije. „Za razliku od postojećeg rada, MILI, kao end-to-end mreža, podstiče rekonstrukciju više osoba čak i sa slika niske rezolucije i značajno poboljšava robusnost na okluzije sa mrežom za predviđanje maski svesne okluzije tako što rafinira fazu detekcije. sa segmentacijom“.
„Rekonstrukcija 3D poza i oblika za pojedince na sceni nadzora omogućiće bolje prepoznavanje radnji/aktivnosti, uključujući interakciju između ljudi, modeliranje ponašanja gomile za simulacije i bezbednosni nadzor i bolje praćenje pojedinaca tokom vremena“, zaključio je Li.