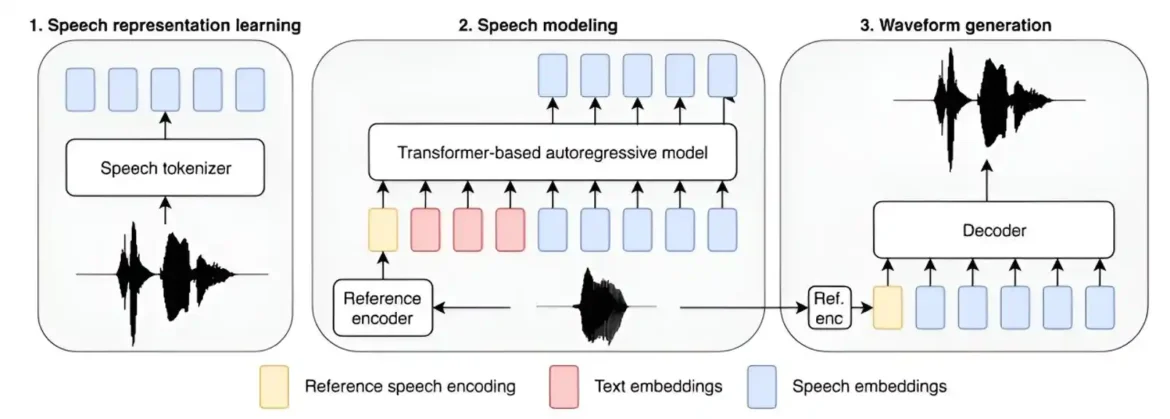
Tim istraživača veštačke inteligencije u Amazon AGI najavio je razvoj onoga što opisuju kao najvećeg modela za pretvaranje teksta u govor ikada napravljen. Pod najvećim podrazumevaju da imate najviše parametara i da koristite najveći skup podataka za obuku. Oni su objavili rad na serveru za preprint arKsiv koji opisuje kako je model razvijen i obučen.
LLM kao što je ChatGPT privukli su pažnju svojom ljudskom sposobnošću da inteligentno odgovaraju na pitanja i kreiraju dokumente visokog nivoa. Ali AI i dalje ulazi u druge glavne aplikacije. U ovom novom naporu, istraživači su pokušali da poboljšaju sposobnost aplikacije za pretvaranje teksta u govor povećanjem broja njenih parametara i dodavanjem bazi za obuku.
Novi model, nazvan Big Adaptive Streamable TTS vith Emergent sposobnosti, (skraćeno BASE TTS) ima 980 miliona parametara i obučen je korišćenjem 100.000 sati snimljenog govora (pronađenog na javnim sajtovima), od kojih je većina bila na engleskom. Tim mu je takođe dao primere izgovorenih reči i fraza na drugim jezicima kako bi omogućio modelu da pravilno izgovori dobro poznate fraze kada ih naiđe — na primer „au contraire“, ili „adios, amigo“.
Tim u Amazonu je takođe testirao model na manjim skupovima podataka, nadajući se da će saznati gde se razvija ono što je postalo poznato u oblasti veštačke inteligencije kao emergentni kvalitet, u kojem je AI aplikacija, bilo da je LLM ili aplikacija za pretvaranje teksta u govor , odjednom se čini da se probija na viši nivo inteligencije. Otkrili su da je za njihovu primenu skup podataka srednje veličine bio mesto gde se dogodio skok na viši nivo, sa 150 miliona parametara.
Takođe su primetili da je taj skok uključivao mnoštvo jezičkih atributa, kao što su sposobnost upotrebe složenih imenica, izražavanja emocija, upotrebe stranih reči, primene paralingvistike i interpunkcije i postavljanja pitanja sa naglaskom stavljenim na pravu reč u rečenica.
Tim kaže da BASE TTS neće biti pušten u javnost – plaše se da bi mogao biti neetički korišćen – umesto toga, planiraju da ga koriste kao aplikaciju za učenje. Oni očekuju da primene ono što su do sada naučili da poboljšaju kvalitet aplikacija za pretvaranje teksta u govor uopšte.


